

Impact
A composite score that represents the overall effectiveness and productivity of development work across all activities (code commits, pull requests, and other development tasks) during a specific time period.
Impact definition
Impact is a way to measure the ‘bigness’ of code changes that are happening, in a way that goes beyond simplistic measurements like lines of code.
Impact attempts to answer the question: “Roughly how much cognitive load did the engineer carry when implementing these changes?”
Impact is a measure of work size that takes this into account. Impact takes the following into account:
- The amount of code in the change
- What percentage of the work is edits to old code
- The surface area of the change (think ‘number of edit locations’)
- The number of files affected
- The severity of changes when old code is modified
- How this change compares to others from the project history
One engineer makes a contribution of 100 new lines of code to a single file. Compare that to another engineer’s contribution, which touches three files, at multiple insertion points, where they add 16 lines, while removing 24 lines. The significance of each contribution can’t be boiled down to just the amount of code being checked in. Even without knowing specifics, it’s likely that the second set of changes were more difficult to implement, given that they involved several spot-edits to old code.
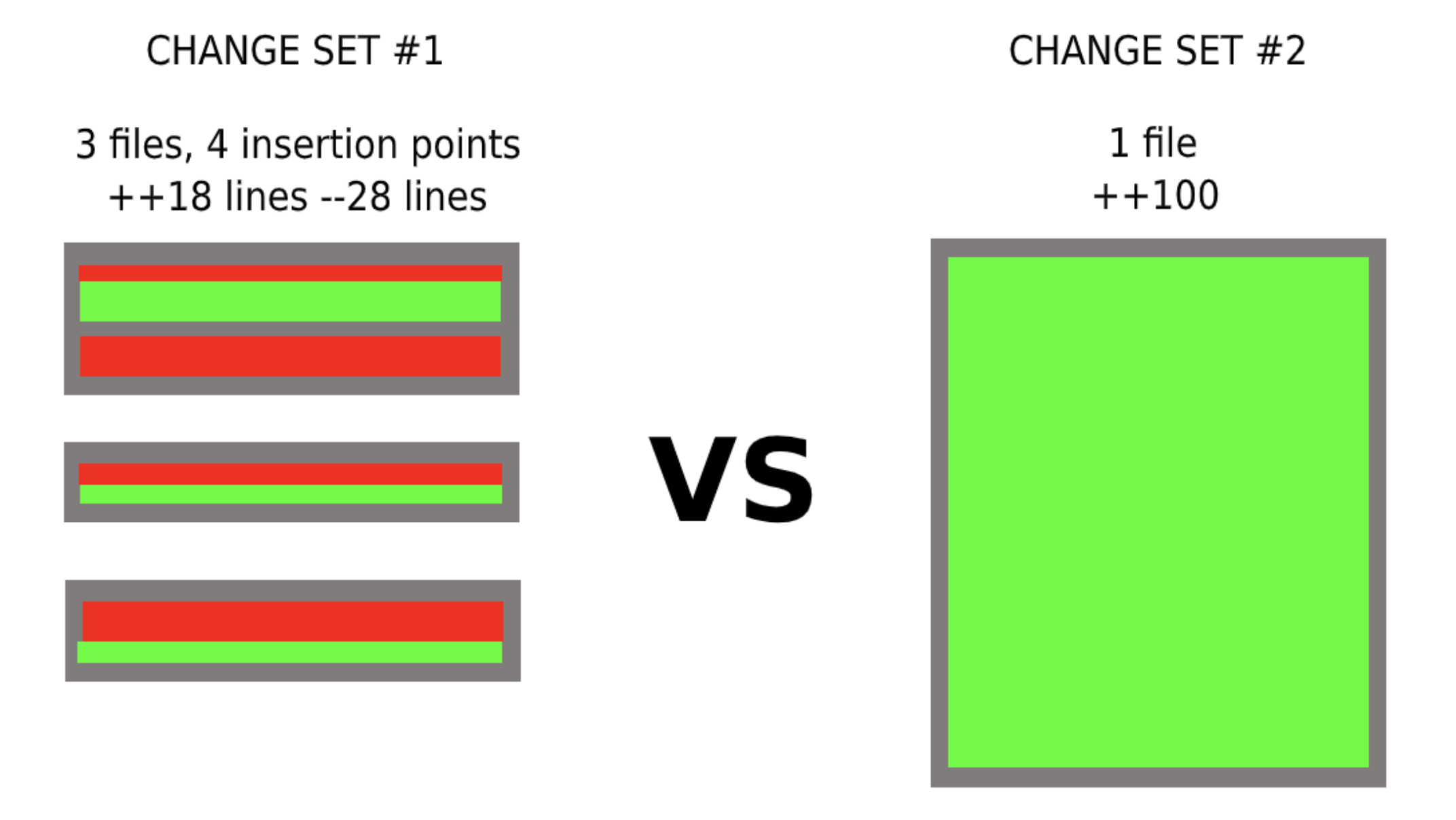
On the left we have someone adding 100 lines of new code to a single file. On the right is an example that represents only 18 lines of new code written, but there’s a bit more going on here:
- this change required modifying previous work
- the edits happened in 4 different locations
- 3 different files were affected
Even without knowing the severity of changes or comparing to historical changes, it’s probably safe to assume that the second contribution was more ‘expensive,’ and therefore carries is higher impact score. Although change set #1 is technically more code, the added complexity of the work happening in change #2 could arguably make that change set at least as much work, and possibly more — even in the simplistic representation above, it’s clear that there’s more than just lines of code at play.
Where to find it
- Health > Benchmark > Add new metric
- Health > Team Insights > Add new metric
Interpretation
- High Impact Values - high productivity across multiple developers, consistent daily activity, good code quality (high scores), efficient work distribution, strong team collaboration.
- Low Impact Values - limited developer activity, inconsistent work patterns, low code quality scores, poor work distribution, team coordination problems.
- Medium Impact Values - normal team performance, reasonable productivity with good quality, maintainable pace for the team.
Custom Dashboards
Don't forget you can anytime include any metric in your Custom Dashboards.
Updated 10 months ago